探索云平台上实时数据流和数据分析的关键方面,包括架构、集成策略和未来发展趋势。
原文链接 ==>�https://dzone.com/articles/real-time-data-streaming-on-cloud-platforms (Nov. 06, 24)
如今,在瞬息万变的数字世界中,企业高度依赖数据来提升客户参与度、做出明智决策并优化运营。因此,随着数据量的持续增长,实时数据和分析变得越来越重要。实时数据使企业能够即时响应不断变化的市场状况,从而在各个行业获得竞争优势。由于其强大的基础设施、可扩展性和灵活性,云数据平台已成为管理和分析实时数据流的最佳选择。
本文探讨了云平台上实时数据流和分析的关键方面,包括架构、集成策略、优势、挑战和未来趋势。
云数据平台和实时数据流 云数据平台和实时数据流改变了组织管理和处理数据的方式。与批量处理(数据按计划间隔存储和处理)不同,实时流处理会在数据生成时立即对其进行处理。云数据平台提供必要的可扩展基础设施和服务,用于摄取、存储和处理这些实时数据流。
使云平台能够高效处理实时数据流复杂性的关键功能包括:
可扩展性。云平台可以自动扩展资源以处理波动的数据量。这使得应用程序即使在高峰负载下也能保持稳定的性能。
低延迟。实时分析系统旨在最大限度地减少延迟,提供近乎实时的洞察,并使企业能够快速响应新数据。
容错性。云平台提供容错系统,确保数据处理不间断,不受硬件故障或网络错误的影响。
集成。这些平台与云服务(用于存储、人工智能/机器学习工具)以及各种数据源集成,以创建全面的数据生态系统。
安全性。高级安全功能(包括加密、访问控制和合规性认证)确保实时数据安全并符合法规要求。
监控和管理工具。基于云的平台提供仪表板、通知和其他监控工具,使企业能够实时观察数据流和处理效率。
下表重点介绍了 AWS、Azure 和 Google Cloud 的关键工具,并着重介绍了它们的主要功能以及它们在实时数据处理和云基础设施管理中的重要性:
CLOUD SERVICE
KEY FEATURES
IMPORTANCE
AWS Auto Scaling - Automatic scaling of resources
- Cost-efficient resource management
Amazon CloudWatch - Monitoring and logging
- Provides insights into system performance
Google Pub/Sub - Stream processing and data integration
- Low latency and high availability
Azure Data Factory - Data workflow orchestration
- Automates data pipelines
Azure Key Vault - Identity management
- Centralized security management
云服务提供商提供各种实时数据流功能。选择平台时,应考虑可扩展性、可用性以及与数据处理工具的兼容性等因素。选择适合您组织架构、安全要求和数据传输需求的平台。
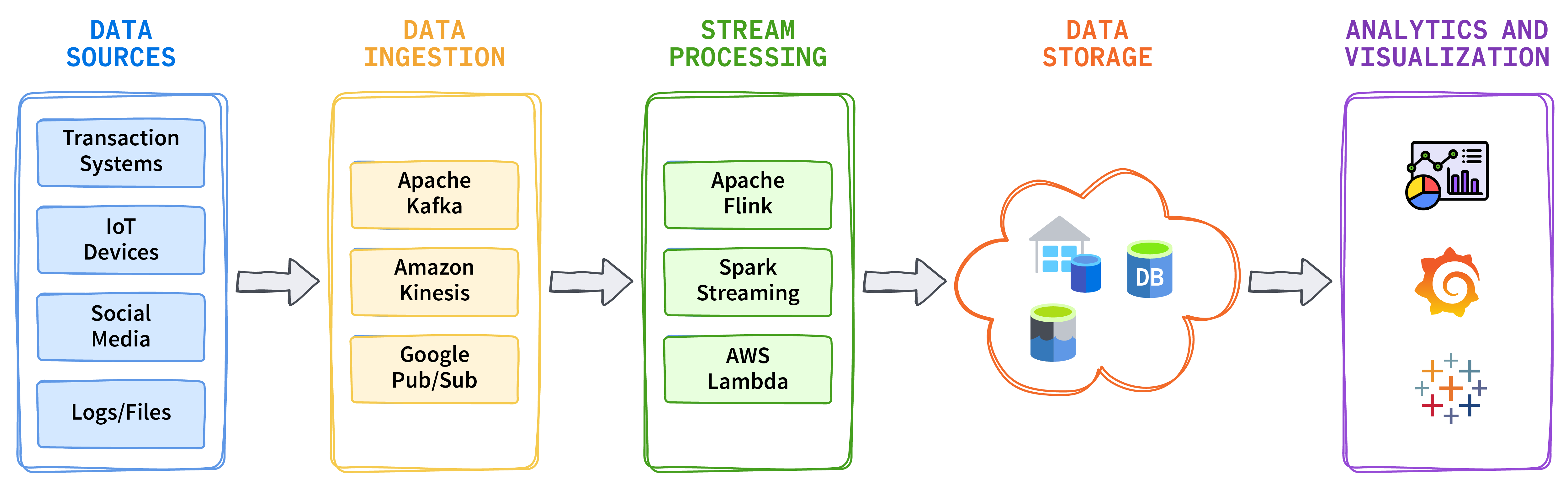
为了支持您的云平台和实时数据流,以下是一些关键的开源技术和框架:
Apache Kafka 是一个分布式事件流平台,用于构建实时数据管道和流式应用程序。
Apache Flink 是一个流处理框架,支持复杂事件处理和有状态计算。
Apache Spark Streaming 是 Apache Spark 的扩展,用于处理实时数据。
Kafka Connect 是一个框架,可帮助将 Kafka 与不同的数据源和存储选项连接起来。可以设置连接器,在 Kafka 和外部系统之间传输数据。
云数据平台上的实时数据架构 实施实时数据分析需要选择适合组织特定需求的架构。
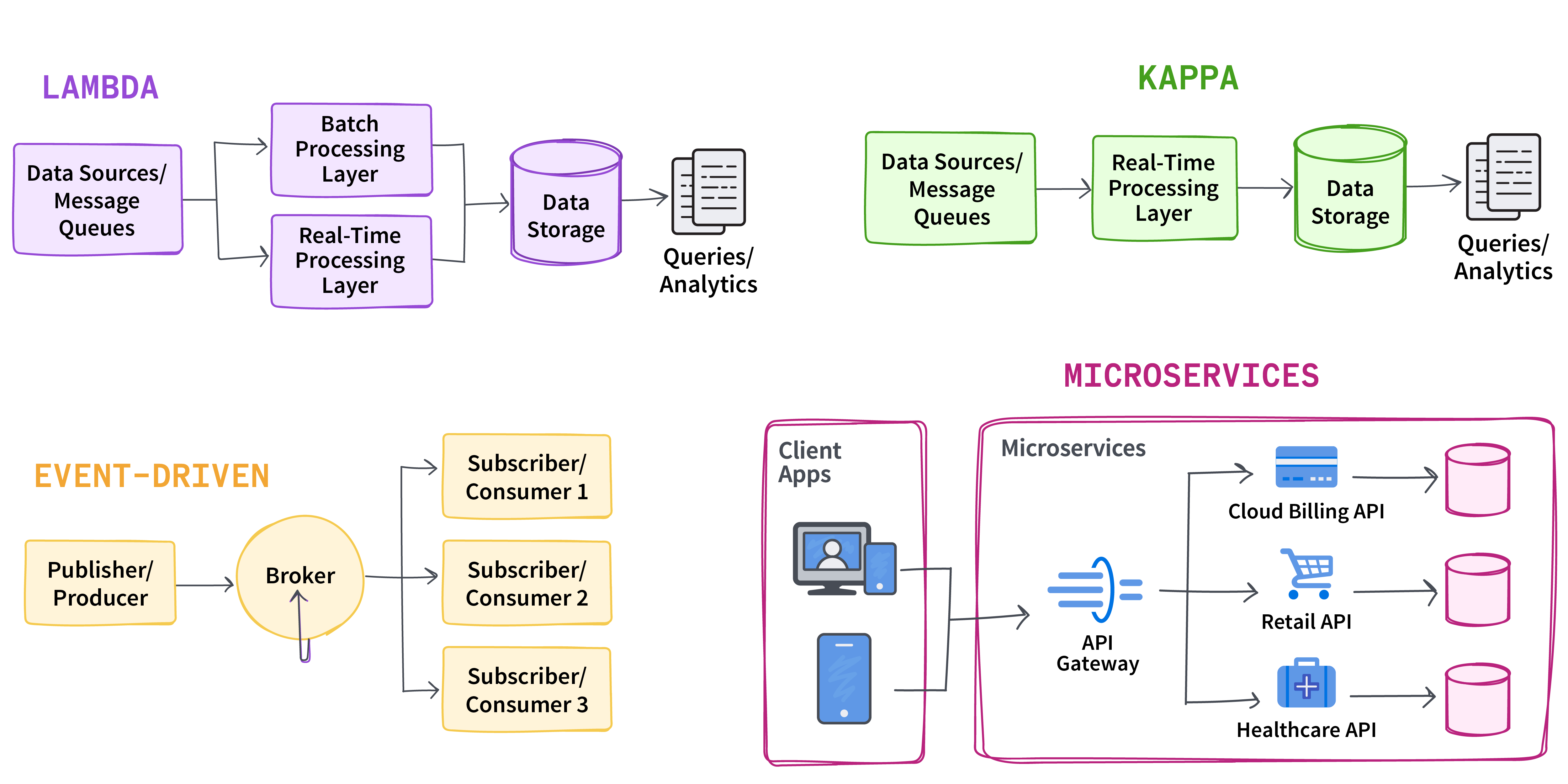
常见架构 不同的数据架构提供了多种管理实时数据的方法。以下是对最流行的实时数据架构的比较:数据架构模式和用例
架构
描述
理想的应用场景
Lambda
这种混合方法结合了批量处理和实时处理;它使用批量处理层处理历史数据,使用实时处理层处理实时数据,并将结果合并以进行全面的分析。
需要历史数据和实时数据的应用程序
Kappa
它简化了 Lambda 架构,专注于实时数据处理,并消除了对批处理的需求。
只需要实时数据的情况
Event driven
根据特定操作或条件触发的事件处理数据,从而实现对数据变化的实时响应。
需要对数据变化进行即时通知的情况
Microservices
采用模块化方法,各个微服务在实时数据管道中处理特定任务,从而提高了可扩展性和灵活性。
需要具备模块化和可扩展性的复杂系统
这些架构为不同的实时数据问题提供了灵活的解决方案,无论需求是整合历史数据、专注于当前数据流、响应特定事件,还是处理包含模块化服务的复杂系统。
图 1. 常见的实时流数据架构
实时数据与云平台的集成 将实时数据与云平台集成正在改变企业处理和理解数据的方式。它利用最新信息提供快速洞察,并增强决策能力。为了确保集成过程的成功,您必须根据实际应用场景选择合适的基础设施、协议和数据处理工具。
关键集成策略包括:
与本地系统的集成。许多组织将云平台与本地系统结合使用,以在混合环境中运行。为了确保数据的一致性和可用性,需要在这些系统之间进行高效的实时数据传输和同步。
与第三方API和软件的集成。将实时分析解决方案与第三方API(例如社交媒体流、金融数据提供商或客户关系管理系统)集成可以提高生成洞察的质量。
数据转换和丰富。在分析之前,实时数据通常需要进行转换和丰富。云平台提供工具来确保数据以正确的格式和上下文进行分析。
数据摄取和处理管道。设置自动化管道来管理从源到目标的数据流,从而提高实时数据处理效率,减少延迟。这些管道可以在云平台上进行调整和跟踪,从而提供灵活性和控制力。
以下是在云平台上设置实时数据管道的步骤:
选择最适合您组织需求的云平台。
确定最适合您的目标和需求的数据摄取工具。Apache Kafka 是最流行的数据摄取工具之一,因为它具有可扩展性和容错性。如果您计划使用托管的 Kafka 服务,则设置过程可能非常简单。对于自托管的 Kafka,请按照以下步骤操作:Kafka topics ),并设置分区以将主题分布到 Kafka 代理上。以下是使用命令行界面 (CLI) 创建主题的示例命令。以下命令创建一个名为 stream_data 的主题,该主题包含 2 个分区(partitions),复制因子(replication factor)为 2:
1 kafka-topics.sh --create --topic stream_data --bootstrap-server your-broker:9092 --partitions 2 --replication-factor 2
配置 Kafka 生产者(Kafka producers ),将实时数据从各种数据源推送到 Kafka 主题:linger.ms、batch.size)。
1 2 3 4 5 6 7 8 9 Sample Kafka Producer configuration properties bootstrap.servers=your-kafka-broker:9092 key.serializer=org.apache.kafka.common.serialization.StringSerializer value.serializer=org.apache.kafka.common.serialization.StringSerializer batch.size=15350 linger.ms=5 retries=2 acks=all
batch.size 设置批处理记录的最大大小(字节),linger.ms 控制等待时间,而 acks=all 设置确保数据在复制完成后才会被确认。
通过设置订阅特定主题的 Kafka 消费者来消费 Kafka 主题中的消息,并处理流式消息。
数据添加到 Kafka 后,您可以使用 Apache Flink、Apache Spark 或 Kafka Streams 等流处理工具实时转换、聚合和丰富数据。这些工具可以同时运行,并将结果发送到其他系统。
为了进行数据存储和保留,您可以创建一个实时数据管道,将流处理引擎连接到 BigQuery、Redshift 或其他云存储服务等分析服务。
收集并保存数据后,使用 Grafana、Tableau 或 Power BI 等工具进行近实时的数据分析和可视化,从而实现数据驱动的决策。
有效的监控、扩展和安全性对于可靠的实时数据管道至关重要。
a. 使用 Kafka 的指标和监控工具,或使用 Prometheus 和 Grafana 进行可视化显示。
将云数据平台与实时数据流相结合:优势与挑战 云平台提供的实时数据和分析功能具有诸多优势,包括:
改进决策。即时访问数据可提供实时洞察,帮助企业做出积极主动且明智的决策,从而影响其业务成果。
提升客户体验。通过个性化互动,企业可以与客户进行实时互动,从而提高客户满意度和忠诚度。
提高运营效率。自动化和实时监控有助于更快地发现和解决问题,减少人工操作,简化运营流程。
灵活性和可扩展性。云平台允许企业根据需求调整资源,因此他们只需为实际使用的服务付费,同时确保业务平稳运行。
成本效益。按需付费模式有助于企业更有效地利用资源,降低基础设施和硬件方面的支出。
尽管优势显著,但在云平台上实施实时数据和分析仍然面临诸多挑战,包括:
数据延迟和一致性。应用程序需要在数据处理速度和数据准确性及一致性之间找到平衡,这在复杂的环境中可能极具挑战性。
可扩展性问题。尽管云平台提供可扩展性,但在实际操作中,处理大规模实时数据处理在规划和优化方面可能相当困难。
集成复杂性。将实时数据流处理与传统系统、本地基础设施或先前实施的解决方案集成可能很困难,尤其是在混合环境中;这可能需要大量的定制工作。
数据安全和隐私。必须在整个过程中维护数据安全,从数据收集到存储和分析。确保实时数据符合 GDPR 等法规,并在不同系统中保持强大的安全性至关重要。
成本管理。云平台具有成本效益;但是,在实时处理大量数据时,成本管理可能会变得具有挑战性。定期监控和管理支出至关重要。
云平台实时数据和分析的未来趋势 云平台实时数据和分析的未来前景广阔,多种趋势将塑造未来的发展格局。以下概述了其中一些趋势:
人工智能和机器学习的创新将对云数据平台和实时数据流产生重大影响。通过将人工智能/机器学习模型集成到数据管道中,可以实现决策流程自动化,获取预测性洞察,并改进数据驱动型应用程序。
随着边缘计算和物联网设备的增长,需要在更靠近数据生成源的地方进行更多实时数据处理。为了降低延迟并最大限度地减少带宽使用,边缘计算允许在位于网络边缘的设备上处理数据。
无服务器计算正在简化实时数据管道的部署和管理,从而减轻企业的运营负担。由于其可扩展性和成本效益,无服务器计算模型(由云服务提供商管理基础设施)正变得越来越普遍,用于实时数据处理。
结论 实时数据和分析正在改变系统的构建方式,而云数据平台提供了高效管理实时数据流所需的扩展工具和基础设施。随着技术的不断进步,那些在云平台上使用实时数据和分析的企业将更有能力在日益数据驱动的世界中蓬勃发展。无服务器架构、人工智能集成和边缘计算等新兴趋势将进一步提升实时数据分析的价值。这些改进将带来数据处理和系统性能方面的新思路,从而影响实时数据管理的未来发展。