软件项目代码健康度评估体系
在《基于DORA指标体系的项目管理.md》学习之后,继续学习针对software engineering的管理和评估指标。
1. 代码数量
用于规模估算。
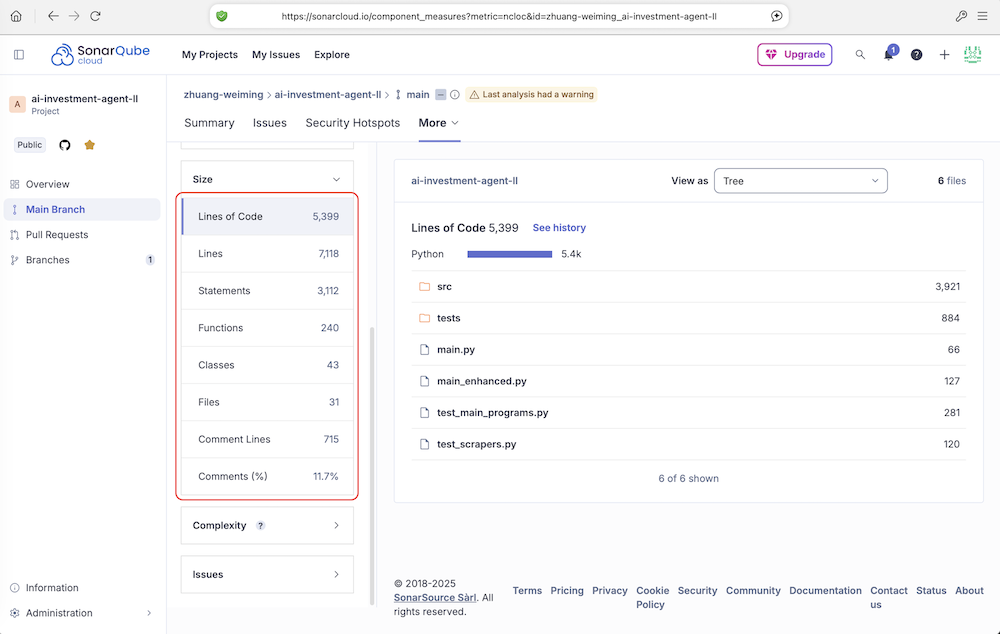
- Lines of Code(代码行数): 所有物理代码行的总数(包括空行和注释)。这是一个最基础的规模指标。
- Lines(行数): 文件中的总行数,包括所有代码行、注释行和空行。这个数字通常比“Lines of Code”大,因为它包含了非代码行。其中的差的行数是注释和空行。
- Statements(语句数): 代码中可执行语句的数量。在不同的编程语言中,语句的定义不同(例如,在Java/C#中,一个分号通常代表一个语句的结束)。这个指标比代码行数更能准确反映程序的逻辑复杂度。一个代码行可能包含多个可执行语句。
- Functions(函数数): 代码中定义的函数(或方法)的总数。反映了代码被分解成的模块数量。函数数量过多或过少都可能意味着设计问题(如函数粒度过细或过粗)。
- Classes(类数): 代码中定义的类(或结构体、接口等)的总数(主要面向对象语言)。反映了面向对象设计的抽象层次和模块数量。
- Files(文件数): 被扫描的源代码文件总数(如
.java,.py,.js文件)。项目物理结构的基本单位数量。 - Comment Lines(注释行数): 专门用于注释的行数。注释有助于理解代码意图。
- Comments(%): 注释行数占总行数(Lines)的比例。
Comments(%) = Comment Lines / (Lines of Code + Comment Lines)注释密度:这个比例没有绝对的好坏标准,通常认为在 10%-30% 之间是比较健康的,但更重要的是注释的质量(解释为什么这么做,而不是重复代码在做什么)。
1.1. Number of Coder vs Non-Coder 编码人数对比非编码人数
它反映了团队的结构、效率、成熟度以及公司的文化导向。编码者是直接从事设计和编写代码工作的工程师。非编码者为编码者提供支持、确保项目成功交付所必需的其他角色。通常包括:项目经理、产品经理、UI/UX设计师、QA/测试工程师、运维/SRE工程师、技术文档工程师、团队领导(如果其编码量很少)等。
1.1.1. 团队成熟度与产品阶段视角
- 早期/创业阶段:比例通常很高。编码者是绝对主力,一人多职。非编码职能可能由创始人或编码者兼任。目标是快速验证想法,推出MVP。
- 成长/扩张阶段:比例开始下降。公司会陆续引入产品经理、专职测试、运维等,以建立流程、保障质量和规模扩张。此时比例变化是健康的标志。
- 成熟/稳定阶段:比例会稳定在一个相对较低的平衡点。团队结构完整,各司其职,专注于优化和稳健创新。
1.1.2. 文化与管理导向视角
- 工程师驱动文化:公司极度信任技术团队,倾向于给工程师更多自主权。可能会维持较高的coder比例,鼓励工程师参与产品讨论和决策。
- 流程与管控驱动文化:公司强调可预测性、风险控制和规范流程。可能会配备更多的项目经理、QA等角色,导致比例较低。
2. 代码质量
当前开放的所有 Issues = 当前开放的Vulnerability + 当前开放的Bug + 当前开放的Code Smell。
2.1. Security(安全性)
- 衡量代码中存在的安全漏洞的数量和严重性。由所有类型为 Vulnerability(漏洞)的 Issues 聚合计算得出的。这些漏洞可能被恶意攻击者利用,导致数据泄露、服务中断、未授权访问等安全问题。SonarQube 会根据通用漏洞评分系统(如 CVSS)将漏洞分为严重、高危、中危、低危等级别。
- 这个指标是“通过”状态,意味着在本次扫描中,代码库没有发现任何“阻断”或“严重”级别的安全漏洞,或者发现的漏洞数量在质量门禁允许的阈值之内。这是最重要的指标之一。
2.2. Reliability(可靠性)
- 衡量代码中存在的Bug(错误)的数量和严重性。它是由所有类型为 Bug(错误)的 Issues 聚合计算得出的。这些Bug不一定能被外部攻击者利用,但会导致程序运行结果不正确、性能下降或直接崩溃(例如,空指针异常、资源泄漏、逻辑错误)。
- 这个指标是“通过”状态,意味着代码中没有“阻断”或“严重”级别的Bug,或者Bug数量在可接受范围内。高可靠性是软件稳定运行的基石。
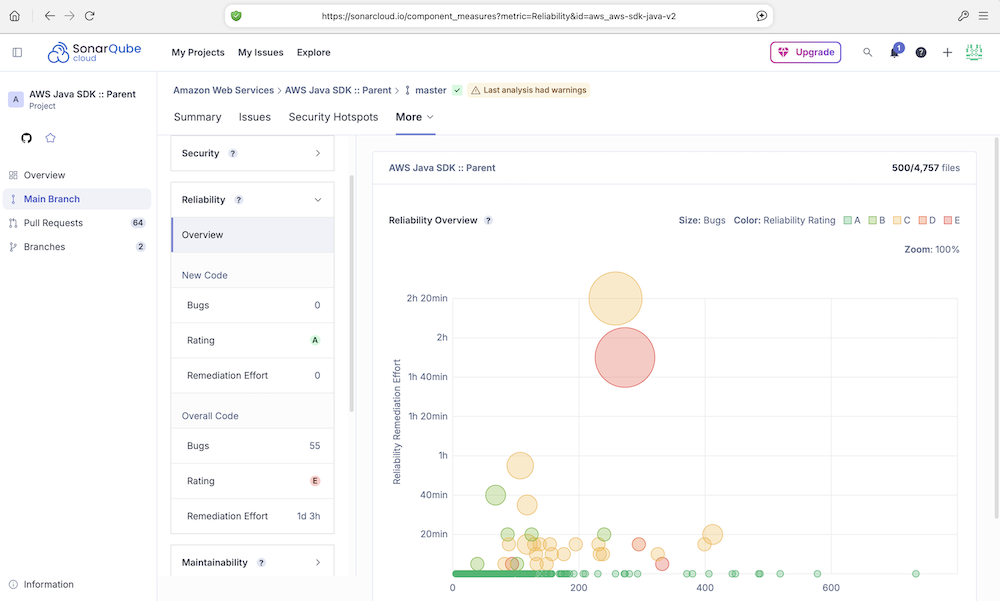
2.3. Maintainability(可维护性)
- 衡量代码的技术债和可维护性。由所有类型为 Code Smell(代码坏味道)的 Issues 聚合计算得出的。它主要关注“代码坏味道”——这些不是错误,而是设计或实现上的缺陷,会导致代码难以理解、修改和扩展(例如,过长的函数、过大的类、重复代码、复杂的条件判断)。技术债以“修复所需时间”来量化(例如,5天3小时)。
- 这个指标是“通过”状态,意味着代码的“坏味道”总量或技术债在预设的门禁之内。高可维护性意味着未来添加新功能或修复问题会更容易,成本更低。
2.4. 测试覆盖度(Coverage)
- Coverage(综合覆盖率)
这是行覆盖率和条件覆盖率的加权综合值。通常,Coverage(综合覆盖率)80%以上的覆盖率就被认为是良好的水平。 - Lines to Cover(可覆盖代码行数)
可被测试覆盖的可执行代码行的总数。 - Uncovered Lines(未覆盖行数)
在“可覆盖代码行”中,没有被任何测试用例执行到的行数。这是测试的“漏洞”。 - Line Coverage(行覆盖率)
被测试覆盖到的代码行所占的百分比。计算公式:(Lines to Cover - Uncovered Lines) / Lines to Cover - Conditions to Cover(可覆盖条件数)
在代码中,所有的条件判断分支的总数。例如,一个if语句有 2 个分支(真和假),一个switch语句有 N 个分支(case 数量)。 - Uncovered Conditions(未覆盖条件数)
在“可覆盖条件”中,没有被任何测试用例走过的分支路径数。有 2 个条件分支(例如,某个if的else分支,或某个case语句)在测试中从未被触发。这是比“未覆盖行”更隐蔽的风险,因为它可能意味着某些边缘情况或错误处理逻辑没有被测试到。 - Condition Coverage(条件覆盖率/分支覆盖率)
被测试覆盖到的条件分支所占的百分比。计算公式:(Conditions to Cover - Uncovered Conditions) / Conditions to Cover
测试用例可能覆盖了代码的“主干道”,但可能遗漏了一些“小路”(如错误情况、边界条件)。
行动建议
- 首要任务:审查那 2 个未被覆盖的条件分支。这些是代码中最危险的部分。
- 找到对应的代码,看看是什么逻辑(很可能是错误处理或边界条件)。
- 为这些分支补充针对性的测试用例,确保它们也能被测试执行到。
- 次要任务:检查那 3 行未被覆盖的代码。它们很可能与未覆盖的分支相关联。补齐分支的测试后,这些行很可能自然就被覆盖了。
2.5. 重复度(Duplications)
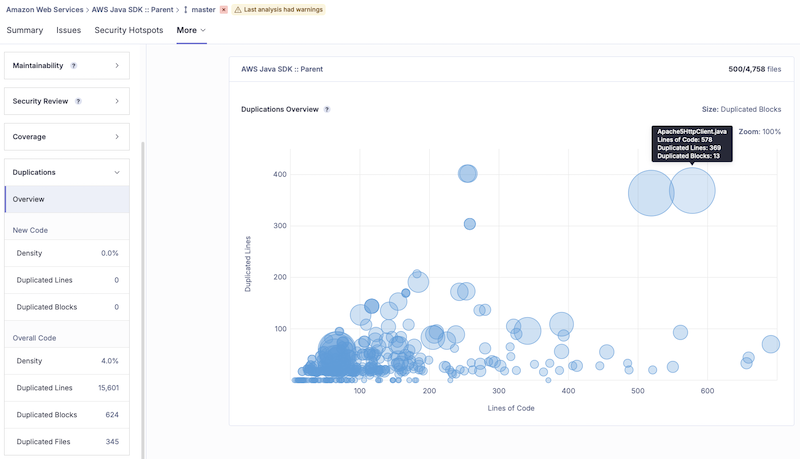
- 指在代码库中重复出现的代码行的比例。SonarQube 会检测完全一致或结构相似的代码块。
- 高重复度是代码的“坏味道”之一,意味着“复制粘贴”编程。这会导致维护困难,因为一处逻辑修改需要在多个地方进行。理想情况下,这个值应该很低。也可能是工程师为了冲高代码行数而复制出的多余代码。
2.6. 复杂度(Complexity)
- Cyclomatic Complexity(圈复杂度):衡量的是代码的结构性复杂度,即“测试这段代码有多难”。
- Cognitive Complexity(认知复杂度):衡量的是代码的可理解性复杂度,即“理解这段代码有多难”。
假设某一页代码的 Cyclomatic Complexity(圈复杂度)- 68
圈复杂度由托马斯·J·麦凯布在1976年提出。它通过计算程序线性独立路径的数量来量化代码的结构复杂度。
基本规则:代码中每出现一个条件分支(如 if, else, case, while, for, catch, &&, ||等),复杂度就 +1。它本质上反映了程序的控制流复杂度。起始值为 1。每遇到一个条件判断分支,值就 +1。
好的,这两个复杂度指标是 SonarQube 中非常核心的代码质量度量项。它们从不同角度衡量代码的复杂程度,而高复杂度是滋生 Bug 和降低可维护性的主要温床。
圈复杂度为 68 是一个非常高的数值,是一个强烈的危险信号。
- 可测试性极差:理论上,你需要设计至少 68 个测试用例才能覆盖这个函数(或类)的所有可能路径。这在实际中几乎不可能完成,意味着代码的测试覆盖率必然很低。
- 维护难度极高:一个拥有 68 条路径的函数,其逻辑必然盘根错节,任何修改都可能产生意想不到的副作用,就像推倒一块多米诺骨牌。
- Bug 高发区:如此复杂的逻辑,很容易在某个罕见的分支条件下出现错误,且难以被发现和修复。
行业通用标准建议: - 1-10:简单、可靠、易于测试的代码。
- 11-20:有点复杂,需要关注。
- 21-50:非常复杂,高风险,急需重构。
- >50:极度复杂,无法测试,是潜在的灾难。你的数值 68 就属于这一级别。
示例
1 | // 示例函数:圈复杂度计算 |
假设某一页代码的Cognitive Complexity(认知复杂度)- 64
SonarSource 公司提出了认知复杂度,旨在更准确地衡量人类程序员理解代码的难度。
圈复杂度的主要问题是:它平等地对待所有分支。但一个嵌套很深的 if语句比几个平级的 if语句更难理解,而圈复杂度计算结果可能是一样的。
认知复杂度的增量规则更智能:
- 鼓励扁平结构:平级的条件分支,增量较小。
- 惩罚嵌套结构:每当出现嵌套的条件分支时,复杂度会显著增加。因为这正是让代码难以理解的主要原因。
- 忽略简写结构:对不影响理解性的结构(如简单的
else)不加分。
如何解读这个值 - 64
和圈复杂度一样,64 也是一个非常高的数值,证实了代码确实极其复杂,并且这种复杂性主要体现在深层嵌套和糟糕的结构上,导致可读性非常差。
- 可读性极差:新成员需要花费很长时间才能理解这段代码的意图。即使是原作者,几周后回来看也可能看不懂。
- 修改成本极高:因为难以理解,所以修改时充满风险,容易引入新的错误。
示例(对比圈复杂度)
1 | // 示例A:平级结构 - 易于理解 |
从例子可以看出,尽管两个例子的圈复杂度接近,但示例B的认知复杂度远高于示例A,这更准确地反映了我们阅读代码时的真实感受:嵌套深的代码难懂得多。
总结与建议
你的代码中 圈复杂度 68 和 认知复杂度 64 这两个数值表明:
- 存在“上帝函数/类”:你的项目中极有可能存在一个或多个非常庞大的函数或类,它试图处理所有事情,违反了“单一职责原则”。
- 代码质量高风险:这是代码库中最需要关注的“坏味道”之一,是 Bug 的温床和维护的噩梦。
重构建议:
- 首要任务:分解。找到那个复杂度最高的函数或类,作为重构的首要目标。
- 提取方法:将大块代码根据逻辑功能提取成多个小函数。给这些新函数起一个清晰易懂的名字。
- 替换算法:有时复杂的条件逻辑可以通过使用设计模式(如策略模式、状态模式)或更优雅的算法来简化。
- 减少嵌套:尽早返回(Early Return)是减少嵌套的利器。将深度嵌套的代码“拉平”。
- 使用多态:如果复杂的分支判断是基于类型,考虑用多态来替代。
解决高复杂度问题是降低技术债、提升代码可维护性最有效的手段之一。
3. 综合的代码质量指数
代码质量综合指数设计方案
3.1. 设计原则
多维度加权:不同指标的重要性不同,需要合理分配权重
归一化处理:将不同量纲的指标标准化到统一尺度
可操作性:指数应能指导具体的改进行动
可视化展示:便于团队理解和跟踪趋势
3.2. 指标体系构建
1 | 代码质量综合指数 (CQ Index) = |
3.3. 各维度评分规则
3.3.1 安全性评分 (25%)
1 | # 基于漏洞密度和加权的评分 |
3.3.2 可靠性评分 (25%)
1 | def reliability_score(bugs): |
3.3.3 可维护性评分 (20%)
基于技术债比率:
1 | def maintainability_score(code_smells, total_lines): |
3.3.4 测试覆盖度评分 (15%)
1 | def coverage_score(overall_coverage, branch_coverage): |
3.3.5 复杂度评分 (10%)
1 | def complexity_score(avg_cyclomatic, avg_cognitive): |
3.3.6 重复度评分 (5%)
1 | def duplication_score(duplication_percentage): |
3.4. 权重配置示例
不同项目类型应使用不同权重模板:
| 项目类型 | 安全性 | 可靠性 | 可维护性 | 测试覆盖度 | 复杂度 | 重复度 | 说明 |
|---|---|---|---|---|---|---|---|
| (金融)核心系统 | 40% | 30% | 15% | 10% | 5% | 0% | 安全合规优先,重复度可忽略 |
| 数据管道项目 | 15% | 40% | 20% | 15% | 10% | 0% | 数据准确性比安全更重要 |
| MVP验证项目 | 10% | 20% | 30% | 25% | 10% | 5% | 快速迭代,可维护性为重 |
| 标准Web应用 | 25% | 25% | 20% | 15% | 10% | 5% | 默认平衡模板 |
基于”标准Web应用”模板(权重见上表)和以下项目数据:
1 | # 输入数据 |
3.5. 质量等级划分
1 | A级 (90-100): 优秀 - 代码质量极高,维护成本低 |
您的项目得分 82.4 属于 B级(良好)
3.6. 可视化仪表板设计
建议创建代码质量仪表板,包含:
- 雷达图:展示6个维度的得分情况
- 趋势图:显示指数随时间的变化
- 改进建议:基于最低分维度提供具体行动项
- 反对团队对比:原DORA团队成员明确反对跨团队对比,因团队业务域、技术栈、历史债务差异巨大,对比会催生”指标博弈”(如刻意不修复低优先级Bug以保分数)。
4. 如何使用
- 原则1: 这些指标应作为团队过程健康度的观测器,用于识别问题区域(如高复杂度模块、重复代码热点),而非考核个人,禁止用于绩效考核、晋升
- 原则2: 指标异常时,管理层应提供资源支持(如排期重构),而非问责
- 原则3: 关注”重复度从8%降到5%”而非”本月得分82.4”
- 原则4: 门禁分级与响应SLA:
| 门禁类型 | 触发条件 | 自动动作 | 人工响应SLA | 升级路径 |
|---|---|---|---|---|
| 强制门禁 | Security / Reliability 的Blocker级问题 | 禁止合并PR | 无法绕过 | 自动阻塞 |
| 警告门禁 | 圈复杂度 >50 或 重复度 >10% | 添加 Warning 标签 | 24小时内 Review | TL评估是否放行 |
| 观察指标 | 注释密度 <5% | 仅记录,不阻塞 | 周会讨论 | EM决定是否调整规范 |
- 安全密集型项目提高安全权重,快速验证型MVP可适当放宽
- 代码质量必须结合部署频率、变更前置时间、失败率等结合DORA指标一起看。代码质量再好,若变更失败率高、交付周期长,仍需反思流程
- 引入热点分析(Hotspot Analysis),结合变更频率和复杂度共同决策重构顺序。
参考链接:
- [SonarQube官方指标定义] https://docs.sonarsource.com/sonarqube-cloud/digging-deeper/metric-definitions
- https://docs.sonarsource.com/sonarqube-cloud/standards/managing-quality-gates/viewing-quality-gate
- https://docs.sonarsource.com/sonarqube-for-vs-code/getting-started/installation
- https://zhuang-weiming.github.io/2025/03/29/%E5%9F%BA%E4%BA%8EDORA%E6%8C%87%E6%A0%87%E4%BD%93%E7%B3%BB%E7%9A%84%E7%BB%A9%E6%95%88%E7%AE%A1%E7%90%86/?highlight=%E7%BB%A9%E6%95%88
- /_posts/基于DORA指标体系的项目管理.md