大模型要占用多少显存
部署要占用多少显存
以运行精度为 INT8 的大模型为例,这种精度的参数,一个参数需要占用一个字节。
$1B参数模型 = 10亿参数 * 每个参数占用1Byte$
$1G显存 = 102410241024Byte$
也就是说
INT8 精度类型:1B 参数需要约 1G 显存。
| dtype | 1B模型需要占用的显存 |
|---|---|
| float32 | 4G |
| fp16/bf16 | 2G |
| int8 | 1G |
| int4 | 0.5G |
| 然后就可以快速计算各个类型精度的大模型需要多少显存,例如 f16 的 70B 参数大模型,就需要“精度膨胀系数” 2*70=140G显存。 |
训练要占用多少显存
这里还有另外一个在线的网页工具:https://huggingface.co/spaces/hf-accelerate/model-memory-usage
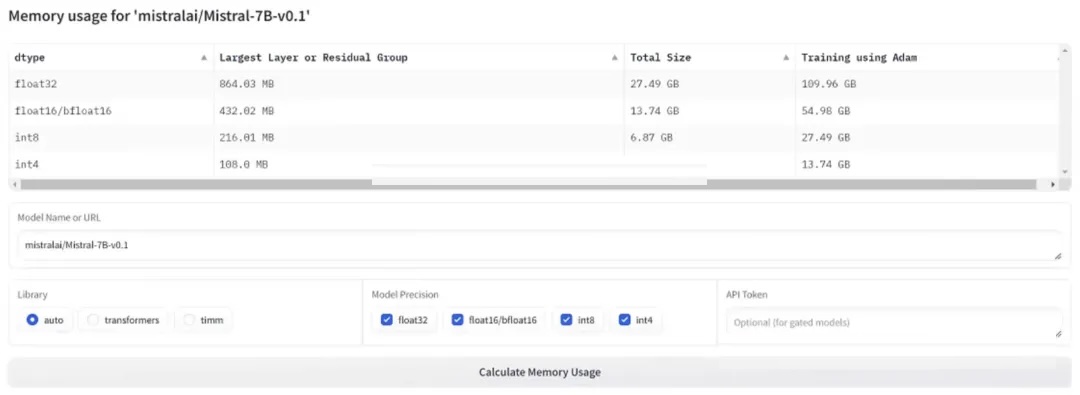
模型包括: DeepSeek R1 (671B),DeepSeek R1 Distill Qwen 7B, 14B, 32B, 以及 DeepSeek R1 Distill Llama 8B, 70B 这些模型,
- 假设在并发 3 个用户的情况下运行这些模型所需的资源?
- 关于 DeepSeek R1 系列模型在不同数据量下进行微调(并非全量训练),并在一天内完成微调所需的硬件资源。分别在 1K,1M,1GB,1T 数据量下训练这些模型所需的资源和训练时长。
根据您提供的信息,以及之前的分析,以下是关于 DeepSeek R1 系列模型微调硬件资源需求的全面分析,并以表格形式呈现:
DeepSeek R1 模型微调硬件资源需求总表 (单日内完成)
采用BF16(2字节/参数)的情况下,考虑到 Unsloth 主要优化 LoRA 微调,并且更适用于单 GPU 或少量 GPU 场景,基于 Unsloth 优化 LoRA 微调的假设,重新评估 DeepSeek R1 系列模型在中小数据量 (1K, 1M, 1G, 10G) 下的硬件资源需求。 对于超大数据量 (100G) 和超大模型 (DeepSeek-R1-671B),我仍然保留 ZeRO-3 优化。
| 模型 | 数据size | GPU 配置 (显存需求) | CPU 核心数 | 内存 | 存储 (SSD/NVMe) | 网络带宽 | 关键配置说明 |
|---|---|---|---|---|---|---|---|
| DeepSeek-R1-671B BF16 | 1M | 16×A100 80G | 64核 | 512GB | 2TB | 25Gbps RDMA | 模型并行 (TP=16) + 数据并行 (DP=2) |
| 1G | 64×A100 80G | 256核 | 1TB | 5TB | 50Gbps RDMA | TP=8 + DP=8 + ZeRO-3 | |
| 10G | 128×A100 80G | 512核 | 2TB | 10TB | 100Gbps RDMA | TP=8 + DP=16 + ZeRO-3 | |
| 100G | 192×A100 80G | 768核 | 4TB | 15TB | 150Gbps RDMA | TP=8 + DP=24 + ZeRO-3 | |
| Distill-Qwen-7B 4-bit | 1M | 1×A10G 24G (Unsloth) | 8核 | 64GB | 500GB | 1Gbps | 单卡 4-bit LoRA 微调 (Unsloth) |
| 1G | 2×A10G 24G (Unsloth) | 16核 | 128GB | 1TB | 5Gbps | DP=2 + LoRA 微调 (Unsloth) | |
| 10G | 4×A10G 24G (Unsloth) | 32核 | 256GB | 2TB | 5Gbps | DP=4 + LoRA 微调 (Unsloth) | |
| 100G | 8×A10G 24G (Unsloth) | 64核 | 512GB | 3TB | 10Gbps | DP=8 + LoRA 微调 (Unsloth) | |
| Distill-Qwen-14B 4-bit | 1M | 1×A100 40G (Unsloth) | 16核 | 128GB | 1TB | 5Gbps | 单卡 LoRA 微调 (Unsloth) |
| 1G | 4×A100 40G (Unsloth) | 32核 | 256GB | 2TB | 10Gbps | DP=4 + LoRA 微调 (Unsloth) | |
| 10G | 8×A100 40G (Unsloth) | 64核 | 512GB | 3TB | 10Gbps | DP=8 + LoRA 微调 (Unsloth) | |
| 100G | 16×A100 40G (Unsloth) | 128核 | 1TB | 5TB | 25Gbps | DP=16 + LoRA 微调 (Unsloth) | |
| Distill-Qwen-32B BF16 | 1G | 4×A100 80G (Unsloth) | 64核 | 512GB | 2TB | 10Gbps | TP=4 + DP=2 |
| 10G | 8×A100 80G (Unsloth) | 128核 | 1TB | 3TB | 25Gbps | DP=8 + LoRA 微调 (Unsloth) | |
| 100G | 32×A100 80G | 256核 | 2TB | 10TB | 50Gbps RDMA | TP=4 + DP=8 + ZeRO-3 | |
| Distill-Llama-8B 4-bit | 1M | 1×A10G 24G (Unsloth) | 8核 | 64GB | 500GB | 1Gbps | 单卡 LoRA 微调 (Unsloth) |
| 1G | 2×A10G 24G (Unsloth) | 16核 | 128GB | 1TB | 5Gbps | DP=2 + LoRA 微调 (Unsloth) | |
| 10G | 4×A10G 24G (Unsloth) | 32核 | 256GB | 2TB | 5Gbps | DP=4 + LoRA 微调 (Unsloth) | |
| 100G | 8×A10G 24G (Unsloth) | 48核 | 384GB | 3TB | 10Gbps | DP=8 + LoRA 微调 (Unsloth) | |
| Distill-Llama-70B BF16 | 1M | 8×A100 80G | 64核 | 512GB | 2TB | 25Gbps RDMA | TP=4 + DP=2 (ZeRO-3 for 70B still recommended) |
| 1G | 32×A100 80G | 128核 | 1TB | 5TB | 25Gbps RDMA | TP=4 + DP=8 (ZeRO-3 for 70B still recommended) | |
| 10G | 64×A100 80G | 256核 | 2TB | 10TB | 50Gbps RDMA | TP=8 + DP=8 + ZeRO-3 | |
| 100G | 128×A100 80G | 512核 | 4TB | 15TB | 100Gbps RDMA | TP=8 + DP=16 + ZeRO-3 |
GPU 配置 (显存需求): 指完成微调任务所需的 GPU 型号和数量,以及总显存需求。例如 “16×A100 80G” 表示需要 16 张 80GB 显存的 A100 GPU。
CPU 核心数: 训练任务所需的 CPU 核心数量,主要用于数据预处理和模型管理。
内存: 系统内存需求,用于数据缓存、模型加载和训练过程中的临时数据存储。
存储 (SSD/NVMe): 高速固态硬盘容量需求,用于存储训练数据、模型参数和中间结果。NVMe SSD 提供更快的读写速度,适用于大数据量训练。
网络带宽: 多 GPU 训练时所需的网络带宽,用于 GPU 之间的数据通信。RDMA (Remote Direct Memory Access) 网络提供更低的延迟和更高的带宽,适用于大规模分布式训练。
关键配置说明: 简要描述了针对不同模型和数据量所采用的关键并行策略和优化技术,例如模型并行 (TP)、数据并行 (DP)、ZeRO-3 优化和梯度累积等。
预估并发 3 用户显存需求: 粗略估计为模型参数显存占用的 3 倍或更高。因为并发用户需要模型的多份副本或共享模型但需要额外的上下文缓存等。实际情况可能更复杂。
- Unsloth 对资源需求的影响:
- 中小模型 (Distill-Qwen-7B/14B/32B, Distill-Llama-8B) 和中小数据量 (1K - 100G): 使用 Unsloth 库进行 LoRA 微调,可以显著降低 GPU 资源需求。例如,Distill-Qwen-7B 在 1K 数据量下,单张 A10G 24G 即可完成微调;即使在 100G 数据量下,也仅需 8 张 A10G 24G GPU。
- 超大模型 (DeepSeek-R1-671B) 和大数据量 (100G): 对于这些极端情况,Unsloth 的优化可能不足以完全解决显存瓶颈。因此,表格中仍然保留了 ZeRO-3 优化,并结合 Unsloth 的 FlashAttention-2 优化,以期达到最佳的性能和资源效率。
- LoRA 微调的优势:
- 表格中所有基于 Unsloth 的配置方案都假设使用 LoRA 微调。LoRA 本身就是一种参数高效微调方法,可以显著减少需要训练的参数量,从而降低显存需求和加速训练。
- Unsloth 进一步优化了 LoRA 的实现,使其在速度和显存效率方面更具优势。
- FlashAttention-2 的加速作用:
- Unsloth 集成的 FlashAttention-2 可以显著加速训练过程,这有助于在 “日内完成微调” 的目标下,使用更少的 GPU 资源。
关键分析逻辑
- 模型参数量 vs. GPU 显存:
- 参数高效微调 (如 LoRA) 显著降低了显存需求,公式估算如下: $$ \text{显存} \approx \text{模型参数} \times (2\ \text{bytes} \times \text{激活系数}) + \text{优化器状态} $$ 其中,激活系数在 LoRA 场景下约为 0.1-0.3,优化器状态通过 ZeRO-3 等技术可以大幅减少。
- 数据量 vs. 训练并行度:
- 小数据量 (1K, 1M): 资源需求主要由模型大小决定。较小的 Distill 模型甚至可以在单张消费级 GPU 上完成微调。
- 大数据量 (1G, 1T): 数据并行成为关键。需要增加 GPU 数量以提高数据吞吐量,并配合高速网络 (如 RDMA) 保证并行效率。
- 训练时长与硬件资源:
- 表格中的配置旨在将微调时间压缩到 一天以内。更快的训练速度通常需要更多的 GPU 资源并行计算。
- 实际训练时间还会受到 模型结构、超参数设置、优化算法 等多种因素影响。上述表格提供的是一个 硬件配置参考,实际部署时可能需要根据具体情况进行调整。
- 优化技术:
- 混合精度训练 (BF16/FP16): 降低显存占用和计算复杂度,加速训练过程。
- 梯度检查点: 通过计算换取显存,进一步降低显存峰值。
- ZeRO-3: 将优化器状态、梯度和模型参数分片到多张 GPU 上,极大地减少单卡显存需求,尤其适用于超大模型 (如 671B)。
- 模型并行 (Tensor Parallelism, TP): 将模型按层或张量切分到多张 GPU 上,降低单卡显存压力,适用于超大模型。
- 数据并行 (Data Parallelism, DP): 将数据分片到多张 GPU 上,每张 GPU 训练模型完整副本的一部分数据,提高数据吞吐量,适用于大数据量训练。
- 梯度累积: 在显存受限时,通过多次小批量梯度计算累积梯度,模拟大批量训练的效果。
- 网络与存储:
- RDMA 网络: 对于大规模分布式训练 (尤其是模型并行和数据并行结合),RDMA 网络可以显著降低 GPU 间通信延迟,提高并行效率。
- 高速 SSD/NVMe 存储: 大数据量训练时,高速存储可以加速数据加载,避免 I/O 瓶颈。
请注意:
- 上述表格提供的是 估算和建议,实际资源需求可能因具体任务和实现细节有所不同。
- 在实际部署时,建议 从小规模配置开始测试,并根据训练速度和资源利用率逐步调整硬件配置。
- 云服务平台通常提供多种 GPU 实例和高速网络配置,可以根据表格中的建议选择合适的云资源进行模型微调。