DeepSeek-R1的核心技术
DeepSeek-R1的实施步骤
DeepSeek-R1本身就是开源的,HuggingFace Open R1 项目 , 李飞飞团队s1项目 , simpleRL-reason 在部分复现DeepSeek R1,还有 TinyZero 项目在复现DeepSeek R1-Zero,又是为何?
根据 DeepSeek-R1 的技术报告,分3个步骤完成这个项目:
- 第1步:用 DeepSeek-R1 蒸馏高质量语料库,来复制R1-Distill模型。
- 第2步:复制 DeepSeek (V3) 用来构建R1-Zero的纯强化学习(RL)pipeline。这可能涉及为数学、推理和代码整理新的大规模数据集。
- 第3步:通过多阶段训练,从基础模型过渡到RL版本。
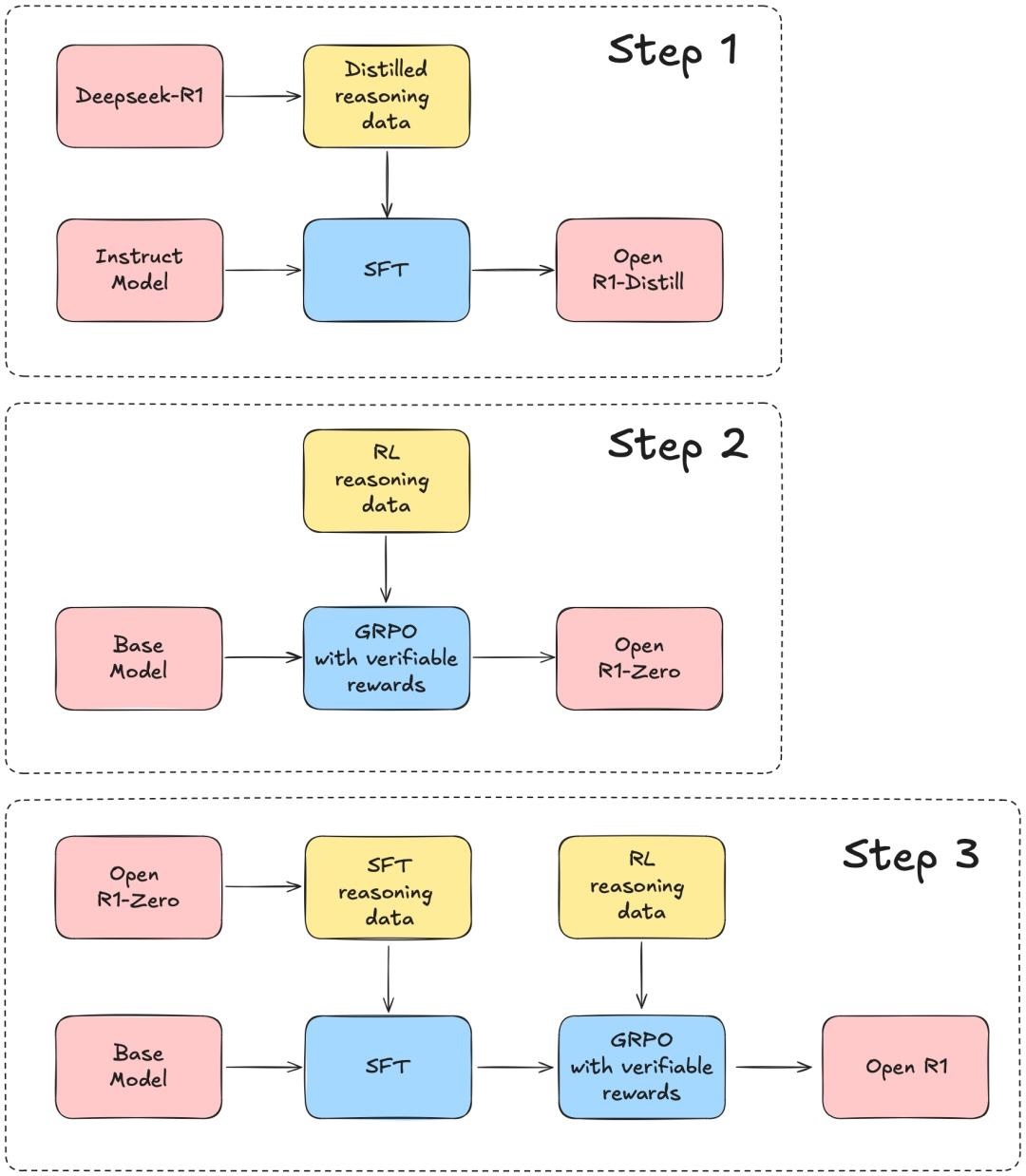
结合DeepSeek的官方技术报告来看,也就是说,Open R1项目首先要实现的,是用R1数据蒸馏小模型,看看效果是不是像DeepSeek说的那么好:
DeepSeek-R1的实施效果
DeepSeek开源了6个用R1蒸馏的小模型,其中蒸馏版Qwen-1.5甚至能在部分任务上超过GPT-4o。
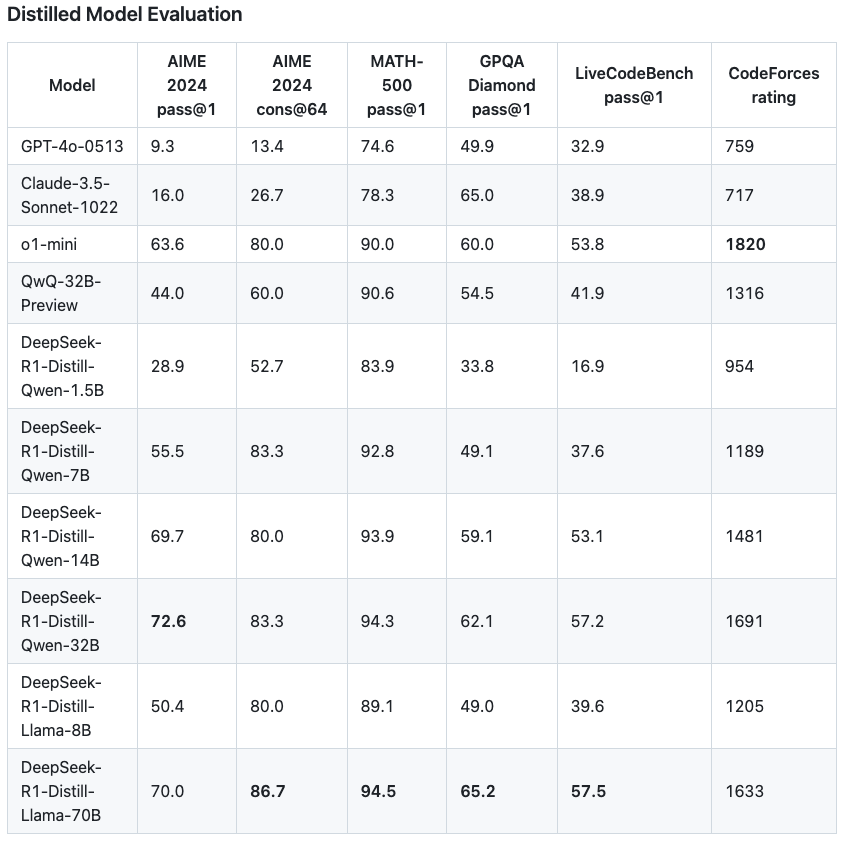
接下来,就是按照DeepSeek所说,不用SFT,单纯依靠RL调教出R1-Zero,在R1-Zero的基础上复刻出性能逼近o1的R1模型。
其中R1技术报告讲到,DeepSeek-R1训练过程中引入了一个多阶段训练流程,具体包括以下4个阶段:
- 冷启动
用数千个长思维链(CoT)样本对基础模型进行监督微调(SFT),为模型提供初始的推理能力。 - 面向推理的强化学习
在第一个SFT阶段的基础之上,用和训练R1-Zero相同的大规模强化学习方法,进一步提升模型的推理能力,特别是应对编程、数学、科学和逻辑推理任务的能力。 - 拒绝采样的监督微调
再次使用监督微调(SFT),提升模型的非推理能力,如事实知识、对话能力等。 - 针对所有场景的强化学习
这次强化学习的重点是让模型行为与人类偏好保持一致,提升模型的可用性和安全性。
Open R1做了什么?
目前,在open-r1 GitHub仓库中,已经可以看到这几个文件:
- GRPO(Grouped Relative Policy Optimization)实现,
grpo.py: trains a model with GRPO on a given dataset.
在 Open R1 发布后,GRPO已整合至TRL最新版本(v0.14,Jan 30, 2025)。该整合方案支持使用单个或多个奖励函数模型进行模型训练。GRPO 实现方案深度集成了 DeepSpeed ZeRO 1/2/3 分布式训练框架以实现多 GPU 扩展,并采用 vLLM 加速生成过程——这正是在线训练方法的主要性能瓶颈。
1 | from datasets import load_dataset |
- 合成数据生成器,
generate.py: generates synthetic data from a model using Distilabel.
R1 技术报告中最引人注目的发现之一是:主模型可用于生成合成推理轨迹,而基于该数据集微调的较小模型可获得与主模型相近的性能提升。因此Open R1自然希望复现该合成推理数据集,使社区能够在其他模型上进行微调实验。
面对 R1 这类超大模型,核心挑战在于高效扩展生成规模。Open R1花费一周时间尝试了多种配置方案:该模型可部署在 2 个 8xH100 节点(16 块 H100 GPU)上,我们最初基于此配置使用 vLLM 作为推理服务器。但很快发现该方案存在性能瓶颈:由于 GPU 的 KV 缓存快速耗尽,吞吐量未达最优且仅支持 8 路并行请求。当缓存耗尽时,占用大量缓存资源的请求会被抢占;若配置为PreemptionMode.RECOMPUTE模式,这些请求将在显存释放后重新调度。为此我们切换至 4x8xH100 节点配置(共 32 块 H100 GPU)。该方案为 32 路并行请求提供了充足的显存余量,基本避免了因 100% 缓存占用导致的请求重新调度问题。初始阶段我们采用批量请求查询 vLLM 服务器,但很快发现批次中的长尾样本会导致GPU利用率波动——新批次需等待前一批次最后一个样本完成后才能开始处理。将批量推理切换为流式处理后,GPU利用率显著稳定。
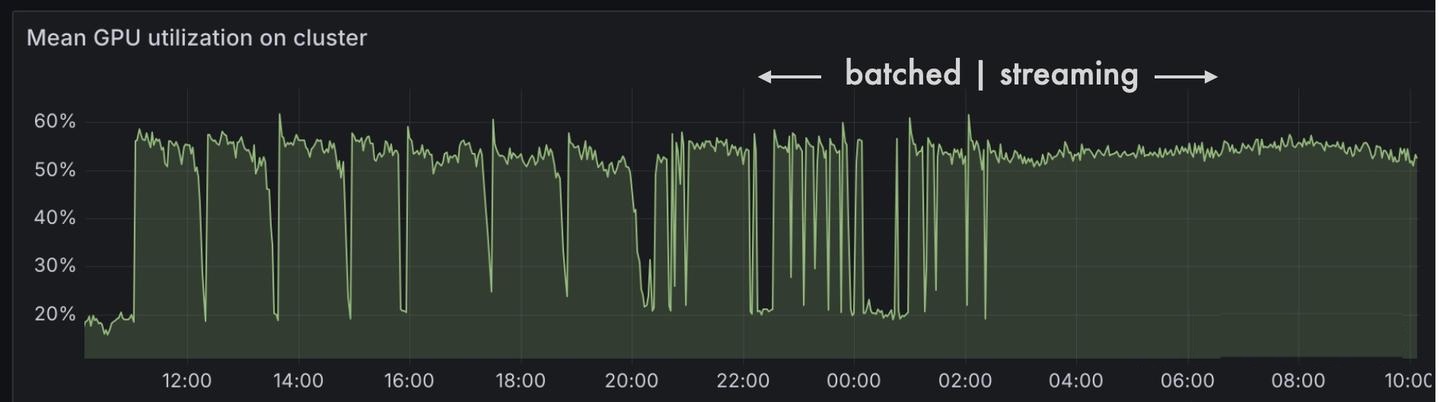
该优化仅需修改vLLM服务器的请求发送代码。批量推理代码如下:
1 | # send requests in batches of 500 |
流式请求的新版代码如下:
1 | active_tasks = [] |
- 实施监督微调训练代码,
sft.py: performs a simple SFT of a model on a dataset.
1 | Train via command line |
- 训练和评估代码,
evaluate.py: evaluates a model on the R1 benchmarks.
数据集
社区在多个与R1相关的数据集项目上非常活跃,以下是一些亮点:
- bespokelabs/Bespoke-Stratos-17k:这是对 Berkeley Sky-T1 数据管线的复制,使用 DeepSeek-R1 创建一个包含问题、推理轨迹和答案的数据集。随后,这些数据被用于通过类似于 R1 论文中的蒸馏方法,微调 7B 和 32B 的 Qwen 模型。
- open-thoughts/OpenThoughts-114k:一个“开放的合成推理数据集,包含 114k 个高质量样本,涵盖数学、科学、代码和谜题”。这是 Open Thoughts 项目的一部分。
- cognitivecomputations/dolphin-r1:一个包含 80 万样本的数据集,样本来自 DeepSeek-R1、Gemini flash 以及来自 DolphinChat 的 20 万样本,目的是帮助训练 R1 风格的模型。
- ServiceNow-AI/R1-Distill-SFT:目前有 17,000 个样本,这是 ServiceNow 语言模型实验室为支持 Open-R1 工作而创建的数据集。
- NovaSky-AI/Sky-T1_data_17k:用于训练 Sky-T1-32B-Preview 的 17k 训练数据。最终数据包含来自 APPs 和 TACO 的 5k 编码数据,以及来自 NuminaMATH 数据集的 AIME、MATH 和 Olympiads 子集的 10k 数学数据。此外,我们还维护了来自 STILL-2 的 1k 科学和拼图数据。使用该数据集训练的模型成本不到 450 美元。
- Magpie-Align/Magpie-Reasoning-V2-250K-CoT-Deepseek-R1-Llama-70B:这个数据集扩展了 Magpie 和方法,通过生成没有起始提示的指令数据来包括推理过程。指令由 Llama 3.1 70B Instruct 和 Llama 3.3 70B Instruct 生成,响应则由 DeepSeek-R1-Distill-Llama-70B 生成。
总结
- SFT后,进步显著,怎么做到的?
一是微调用的训练数据起到了一定作用;二是强制让模型延长思考时间(test time scaling),具体做法叫做(Budget Forcing)预算强制,也就是强制限制模型使用最大或最小 tokens 进行推理,以此控制模型的思考长度。
为了尽可能延长模型的思考,他们将模型的思考放在标签内,当结束后,以 final answer 给出答案,同时,当 LLM 即将停止思考时,会强制输出 Wait 来迫使模型继续思考,通过这样的方式,模型会进入反思,并可能会发现自己的错误。
推理时插入的“Wait”,也许会像当初的 Step by Step 一样,成为一个魔法 token。“这或许就是古人‘三思而后行’的哲学吧!” - R1 训练的步骤总结:
1)精心选择若干条(如 8000 条)高质量的数据,
2)通过让 Gemini/DeepSeek V3 补充完善思维链COT之后作为数据集,
3)以开源的大模型(如 Qwen2.5-32B,Llama 3.1)为基座微调出结果(如 R1)。
4)最后,在模型输出时,用(Budget Forcing)预算强制方法强行拉长模型的思考时长和输出 token,结果发现其在特定测试集上进步显著。