关于AI-LLM测评
根据Google Gemini团队的论文 - https://arxiv.org/pdf/2312.11805 (page 8)来看,测评涵盖了:
- MMLU (Massive Multitask Language Understanding): 这是一个综合性的基准测试,用于衡量模型在多任务语言理解方面的能力。它包含了多个子任务,涉及不同的领域和语言,旨在全面评估模型的语言处理能力。
- GSM8K (Grade-school Math 8K): 这是一个数学问题解答的数据集,包含了小学级别的数学问题。它用于测试模型解决基础数学问题的能力。
- MATH: 这个术语可能指的是一个更广泛的数学问题解答数据集,它可能包含了不同难度级别的数学问题,用于评估模型的数学推理和解答能力。
- BIG-Bench-Hard: 这是BIG-Bench(Broad Institute General Language Benchmark)的一个子集,包含了更难的任务。BIG-Bench是一个用于评估语言模型在广泛任务上性能的基准测试。
- HumanEval: 这是一个用于评估模型在特定任务上性能的基准测试,通常与人类的表现进行比较。它可能包含了多种类型的任务,如编程任务或自然语言生成任务。
- Natural2Code: 这是一个评估模型将自然语言转换为代码能力的数据集。它用于测试模型在编程语言理解和代码生成方面的能力。
- DROP (Discrete Reasoning Over Paragraphs): 这是一个阅读理解和推理的数据集,要求模型对段落进行推理并解决基于段落内容的问题。
- HellaSwag: 这是一个用于评估模型在多步推理和情境理解方面能力的基准测试。它包含了多个情境,模型需要根据给定的故事线索选择合适的结局。
- WMT23: 这是Workshop on Machine Translation(机器翻译研讨会)2023年的缩写,它是一个专注于机器翻译领域的国际会议,通常包含最新的研究成果和技术进展。WMT也组织机器翻译系统的评估和竞争,WMT23可能指的是该年会议中使用的机器翻译基准测试。
改论文中,还有更多的测试数据集。
根据 https://gpt4all.io/index.html 来看,测评涵盖了:
- BoolQ: BoolQ(Boolean Questions)是一个数据集,专门用于评估模型理解自然语言中是/否问题的能力。它要求模型不仅要回答问题,还要判断问题是否是布尔类型(即答案为真或假)。
- PIQA: PIQA(Paraphrased Image Question Answering)是一个图像问答数据集,它要求模型对图像内容进行理解,并回答有关图像的问题,这些问题是以释义或改写的形式提出的。
- HellaSwag: HellaSwag是一个多步推理和常识问答的数据集,它包含了一系列的情境,模型需要根据给定的故事线索选择合适的结局。这个数据集旨在测试模型的推理能力和对常识的掌握。
- WinoGrande: WinoGrande是一个大规模的、多样化的、高质量的问答数据集,它包含了大量的问题和答案对,用于评估模型在开放域问答任务上的性能。
- ARC-e: ARC-e(AI2 Reasoning Challenge - Elementary)是一个评估模型在一系列考试类型问题上的表现的基准测试。它旨在测试模型的知识和推理能力。
- ARC-c: ARC-c(AI2 Reasoning Challenge - Complex)是ARC-e的进阶版本,包含了更复杂的推理挑战,需要模型具备更高级的推理技巧。
- OBQA: OBQA(Open-Book Question Answering)是一个问答任务,其中模型在回答问题时可以访问给定的文本或书籍。这个任务测试模型的理解和推理能力,同时考虑到它可以访问额外的信息源。
由此看来,https://www.baichuan-ai.com/home,目前给出的测评结果来看,还需要继续努力。
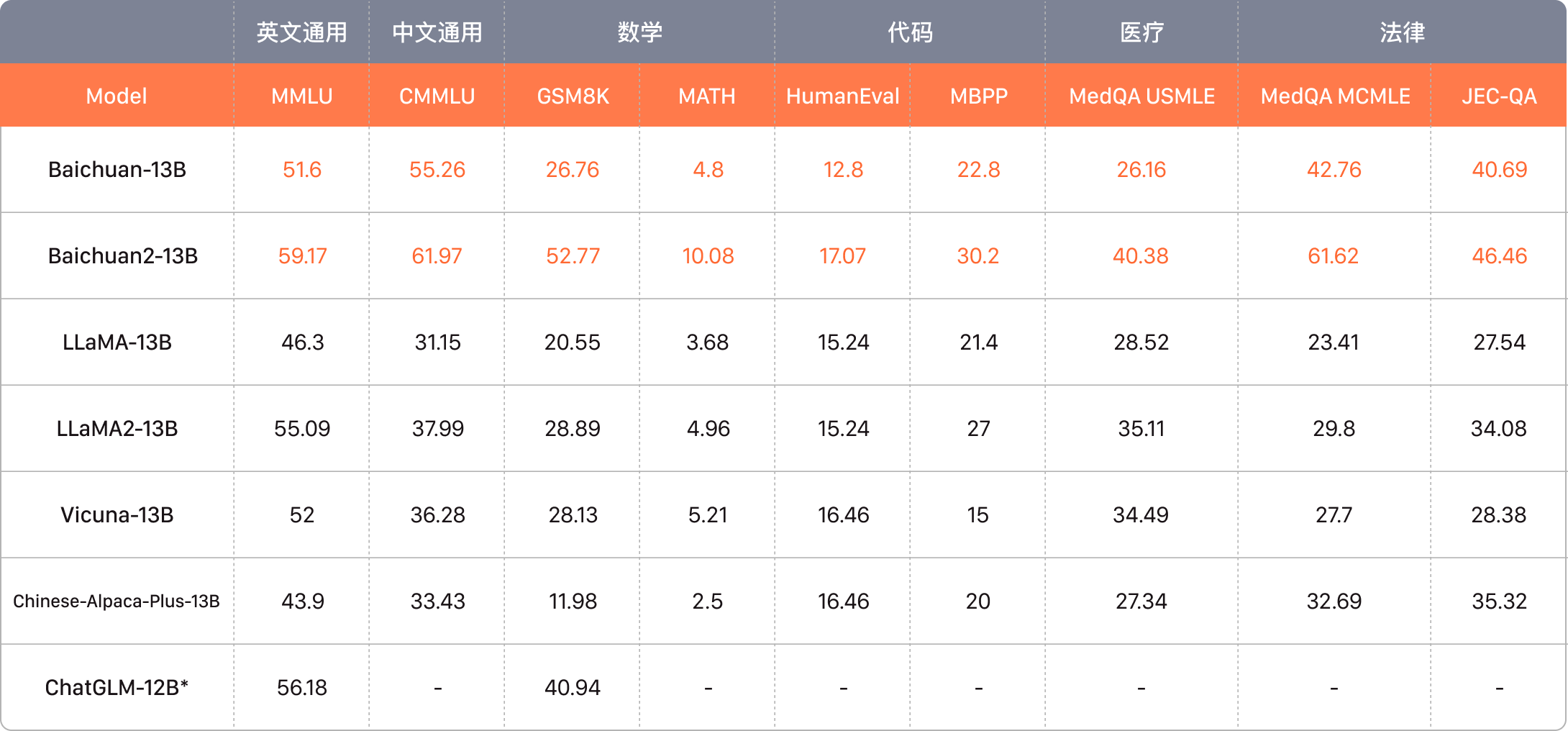
不仅是分数上,而且在测试的范围上,都有相当大的差距存在。