CPU Profiling Golang 提供了 pprof 包(runtime/pprof)用于输出运行时的 profiling 数据,这些数据可以被 pprof 工具(或者 go tool pprof,其为 pprof 的变种)使用。通常我们这样来使用 pprof 包:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 1 2 var cpuprofile = flag.String("cpuprofile" , "" , "write cpu profile to file" )3 func main () 4 flag.Parse()5 6 if *cpuprofile != "" {7 8 f, err := os.Create(*cpuprofile)9 if err != nil {10 log.Fatal(err)11 }12 13 pprof.StartCPUProfile(f)14 defer pprof.StopCPUProfile()15 }16 ...
假定我们编写的一个程序 mytest 中加入了上述代码则可以执行并生成 profile 文件:
1 ./mytest -cpuprofile=mytest.prof
这里,我们生成了 mytest.prof profile 文件。有了 profile 文件就可以使用 go tool pprof 程序来解析此文件:
1 go tool pprof mytest mytest.prof
pprof 程序中最重要的命令就是 topN,此命令用于显示 profile 文件中的最靠前的 N 个样本(samples),例如(此例为 http://blog.golang.org/profiling-go-programs 中的例子):
1 2 3 4 5 6 7 8 9 10 11 12 1 (pprof) top10 2 Total: 2525 samples 3 298 11.8% 11.8% 345 13.7% runtime.mapaccess1_fast64 4 268 10.6% 22.4% 2124 84.1% main.FindLoops 5 251 9.9% 32.4% 451 17.9% scanblock 6 178 7.0% 39.4% 351 13.9% hash_insert 7 131 5.2% 44.6% 158 6.3% sweepspan 8 119 4.7% 49.3% 350 13.9% main.DFS 9 96 3.8% 53.1% 98 3.9% flushptrbuf 10 95 3.8% 56.9% 95 3.8% runtime.aeshash64 11 95 3.8% 60.6% 101 4.0% runtime.settype_flush 12 88 3.5% 64.1% 988 39.1% runtime.mallocgc
开启 CPU profiling 后,Golang 程序在 1 秒钟会停顿 100 次,每次停顿都会记录 1 个样本。上例中,前两列表示运行的函数的样本数量(the number of samples in which the function was running)和占总样本数的百分比,例如说 runtime.mapaccess1_fast64 函数在 298 次采样中(占总采样数量的 11.8%)正在运行。第三列表示前几行样本数量总和占总样本数的百分比(第二行 22.4% 为 11.8% + 10.6%)。第四、五列表示出现的函数的样本数量(the number of samples in which the function appeared)和占总样本数的百分比,这里“出现的函数”指的是在采样中正在运行或者等待某个被调用函数返回的函数,换句话就是采样中那些位于调用栈上的函数。我们可以使用 -cum(cumulative 的缩写)flag 来以第四、五列为标准排序。需要注意的是,每次采样只会包括最底下的 100 个栈帧(stack frames)。
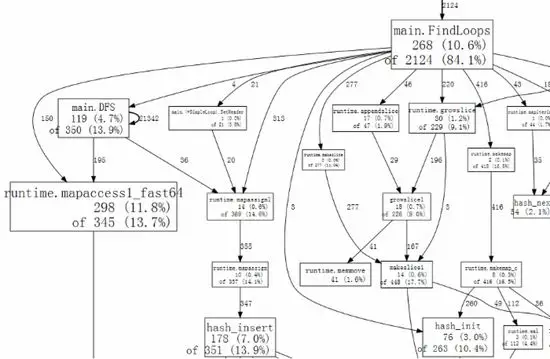
使用 web 命令能够以图形化的方式(SVG 格式)显示函数调用关系。例如(图片来源于 http://blog.golang.org/profiling-go-programs ):
这里每个方块的大小由运行的函数的样本数量决定(这样就能方便的一眼看到热点函数)。箭头表示的是调用关系,箭头上的数字表示的是采样到的调用次数。web 命令还可以指定显示特定的函数,例如:
当我们有大致的想法(也就是确定热点函数)后,就可以深入特定的函数。我们使用 list 命令(此例为 http://blog.golang.org/profiling-go-programs 中的例子):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 1 (pprof) list DFS 2 Total: 2525 samples 3 ROUTINE ====================== main.DFS in /home/rsc/g/benchgraffiti/havlak/havlak1.go 4 119 697 Total samples (flat / cumulative) 5 3 3 240: func DFS(currentNode *BasicBlock, nodes []*UnionFindNode, number map[*BasicBlock]int, last []int, current int) int { 6 1 1 241: nodes[current].Init(currentNode, current) 7 1 37 242: number[currentNode] = current 8 . . 243: 9 1 1 244: lastid := current 10 89 89 245: for _, target := range currentNode.OutEdges { 11 9 152 246: if number[target] == unvisited { 12 7 354 247: lastid = DFS(target, nodes, number, last, lastid+1) 13 . . 248: } 14 . . 249: } 15 7 59 250: last[number[currentNode]] = lastid 16 1 1 251: return lastid
上例中,第一列为运行到此行时的样本数,第二列为运行到此行或从此行调用的样本数,第三列为行号。如果需要显示汇编,可以使用命令 disasm(使用命令 weblist 可以同时显示源码和汇编代码, 这里 有一个范例)。通过样本数,我们可以定位到热点行,然后考虑适合的优化策略。
pprof 包 pprof 包进行 profiling 有两种方式:
采样。CPU Profiling 需要不断采样,(如上所述)pprof 包提供了一套特殊的 API(StartCPUProfile / StopCPUProfile)
快照。下面详细谈这种方式(同样可以使用 go tool pprof 程序来解析输出的 profile 文件)
pprof 包预先定义了(还可以自己扩展)4 种快照模式:
goroutine,当前所有 goroutines 的 stack traces
heap,所有的堆内存分配(为降低开销仅获取一个近似值,To reduce overhead, the memory profiler only records information for approximately one block per half megabyte allocated (the “1-in-524288 sampling rate”), so these are approximations to the actual counts)
threadcreate,致使新系统线程创建的 stack traces
block,致使在同步原语上阻塞的 stack traces
相关 API 具体用法如下:
1 2 3 4 1 2 p := pprof.Lookup("heap" )3 4 p.WriteTo(w, 0 )
这里的 WriteTo 方法原型为:
1 1 func (p *Profile) int ) error
其中 debug 参数:
为 0 时,仅仅输出 pprof(程序)需要的十六进制地址
为 1 时,输出时增加函数名和行号,这样无需工具也可以阅读此 profile
为 2 时,并且当输出 goroutine profile 时,输出的 goroutine 栈的格式为未 recovered panic 时的格式
memory profiling 以 https://blog.golang.org/profiling-go-programs 中的例子为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 1 2 var memprofile = flag.String("memprofile" , "" , "write memory profile to this file" )3 ...4 5 FindHavlakLoops(cfgraph, lsgraph)6 if *memprofile != "" {7 f, err := os.Create(*memprofile)8 if err != nil {9 log.Fatal(err)10 }11 12 pprof.WriteHeapProfile(f)13 14 f.Close()15 return 16 }
使用 go tool pprof 程序打开生成的 profile 文件:
1 2 3 4 5 6 7 1 (pprof) top5 2 Total: 82.4 MB 3 56.3 68.4% 68.4% 56.3 68.4% main.FindLoops 4 17.6 21.3% 89.7% 17.6 21.3% main.(*CFG).CreateNode 5 8.0 9.7% 99.4% 25.6 31.0% main.NewBasicBlockEdge 6 0.5 0.6% 100.0% 0.5 0.6% itab 7 0.0 0.0% 100.0% 0.5 0.6% fmt.init
这里显示了函数当前大致分配的内存。类似 CPU profiling,通过 list 命令查看函数具体的内存分配情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 1 (pprof) list FindLoops 2 Total: 82.4 MB 3 ROUTINE ====================== main.FindLoops in /home/rsc/g/benchgraffiti/havlak/havlak3.go 4 56.3 56.3 Total MB (flat / cumulative) 5... 6 1.9 1.9 268: nonBackPreds := make([]map[int]bool, size) 7 5.8 5.8 269: backPreds := make([][]int, size) 8 . . 270: 9 1.9 1.9 271: number := make([]int, size) 10 1.9 1.9 272: header := make([]int, size, size) 11 1.9 1.9 273: types := make([]int, size, size) 12 1.9 1.9 274: last := make([]int, size, size) 13 1.9 1.9 275: nodes := make([]*UnionFindNode, size, size) 14 . . 276: 15 . . 277: for i := 0; i < size; i++ { 16 9.5 9.5 278: nodes[i] = new(UnionFindNode) 17 . . 279: } 18... 19 . . 286: for i, bb := range cfgraph.Blocks { 20 . . 287: number[bb.Name] = unvisited 21 29.5 29.5 288: nonBackPreds[i] = make(map[int]bool) 22 . . 289: }
有了这些信息,我们就可以着手进行优化了。